For the reasons explained above, we introduce a new approximation, the semi-linear confidence boundary, which outperforms the confidence ellipse as an approximation to the boundary of the confidence prediction region.
The geometrical idea is as follows. The boundary of the confidence
ellipse is indeed an ellipse
![]() in the Y plane; the
points on it come from an ellipse
in the Y plane; the
points on it come from an ellipse
![]() in the orbital
elements space X. The image of the ellipse
in the orbital
elements space X. The image of the ellipse
![]() is a curve
is a curve
![]() in the Y plane; by the
Jordan curve theorem,
in the Y plane; by the
Jordan curve theorem,
![]() is the boundary of a region
is the boundary of a region
![]() in the Y plane;
in the Y plane;
![]() is a subset of
is a subset of
![]() ,
the prediction confidence region, and is a much better
approximation than
,
the prediction confidence region, and is a much better
approximation than
![]() .
.
 |
 |
 |
To compute the semi-linear confidence boundary we can proceed as
follows. The rows of the Jacobian matrix DF(X*) define a
2-dimensional subspace; let us decompose
![]() into a component
E in this subspace, and a component L in the 4-dimensional
subspace orthogonal to the former. Let KE be the ellipse in the Espace corresponding to the confidence ellipse Klin; it is the
boundary of the orthogonal projection of the confidence ellipsoid on
the E space.
into a component
E in this subspace, and a component L in the 4-dimensional
subspace orthogonal to the former. Let KE be the ellipse in the Espace corresponding to the confidence ellipse Klin; it is the
boundary of the orthogonal projection of the confidence ellipsoid on
the E space.
Then the formulas of Section 2.3, Case 2, can be used; in particular
The image of KE by the above formula is an ellipse which belongs to
the boundary of the confidence ellipsoid and maps into KE by the
orthogonal projection, and into Klin by DF; therefore, it is
KX (this is an existence proof as well as an algorithm to compute
the points on this ellipse). The semi-linear confidence boundary can
thus be computed by predicting the observations corresponding to the
points of KX, that is:
![]() .
.
Note that to explicitly compute KN by the above definition requires to compute a full orbit, with N-body model, for each point on KX, that is for each set of orbital elements on a curve, from time t0to time t1. In practice, this is of course done only for a finite number of points, e.g. a few tens in the easy cases, a few hundred when the shape of the curve is complex.
 |
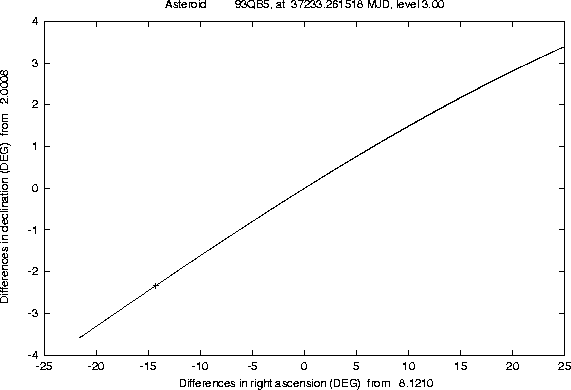 |
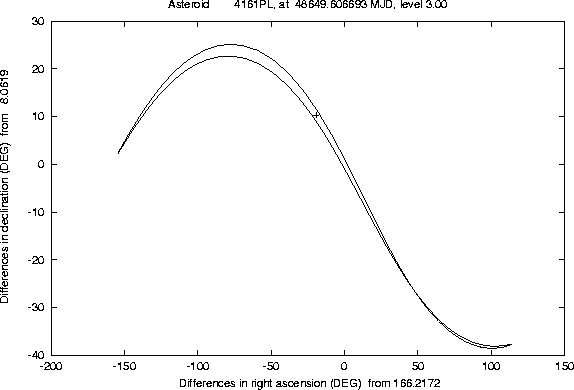
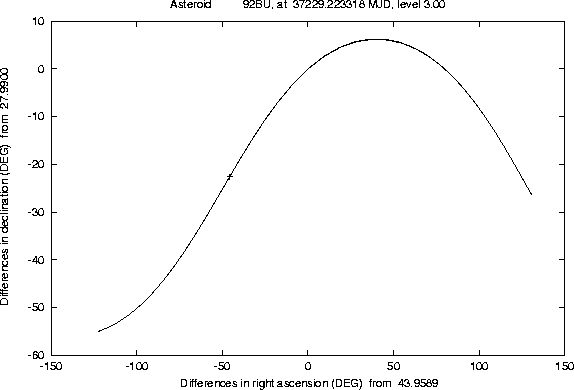
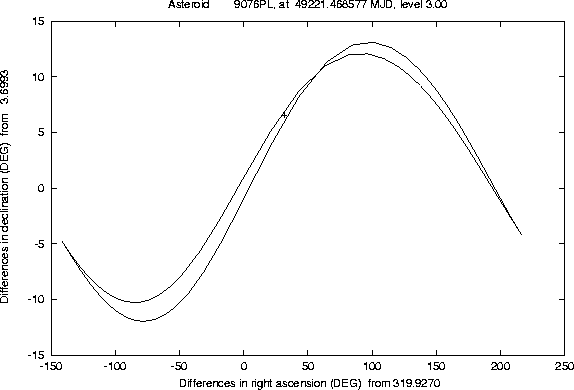
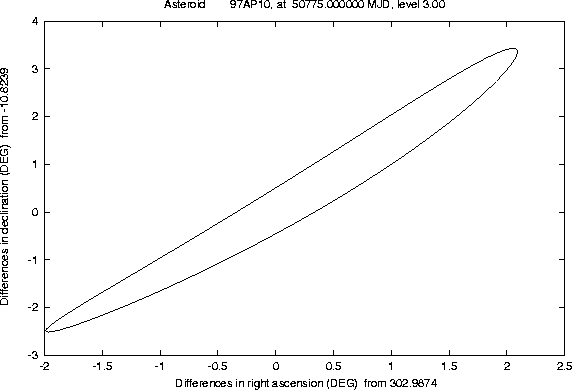
The Figures 1-2 and
4-5 show examples of this semi-linear
confidence boundary, computed for lost asteroids which have later been
recovered, as a result of the use of another algorithm, of the orbit
identification class [Sansaturio et al. 1996]. All the examples of
this kind we have tested show that the recovery observations are
inside the region
![]() ,
bounded by
,
bounded by
![]() ,
with
,
with
![]() ;
only in one case (which turns out to be a precovery, that
is with t1<t0) it is necessary to extend to
;
only in one case (which turns out to be a precovery, that
is with t1<t0) it is necessary to extend to ![]() ,
which
still is not a very large value, given the uncertainties in the
normalisation.
,
which
still is not a very large value, given the uncertainties in the
normalisation.
There are a number of technicalities, involved in the preparation of these Figures, which we can not explain in detail. Even a curve can only be computed as a discrete set of points; if the software is efficient enough, e.g. because of the appropriate use of the approximation described in Section 4.2, it is possible to compute many such points, but when the curve has a ``wild'' behaviour (a very large and rapidly changing curvature) some defects are apparent. These cannot be removed by computer graphics tricks; actually we have used the most simple method to draw the curve, by joining the points with straight line segments, to prevent the risk of hiding the wild behaviour of the boundary with a curve drawing algorithm including a too strong smoothing.
One problem, which is apparent in many of these examples
(e.g. Figure 4), is that
![]() is often not a
simple curve; this in particular implies that it is not the boundary
of the image by F of the inside of
is often not a
simple curve; this in particular implies that it is not the boundary
of the image by F of the inside of
![]() .
Another way of
stating the same problem is the following: it is not always the case
that
.
Another way of
stating the same problem is the following: it is not always the case
that
![]() for
for
![]() .
Anyway, when the confidence ellipse Klin is distorted by strong
nonlinearity of F, the curve KN is not convex.
.
Anyway, when the confidence ellipse Klin is distorted by strong
nonlinearity of F, the curve KN is not convex.
The two effects mentioned above imply that the use of some human
intelligence is required to look at the plots such as Figure 4 and to
decide that a given observation belongs to the confidence region. The
method of computing a number of points on the curve
![]() for
some reasonable
for
some reasonable ![]() ,
then plotting these points, is therefore very
effective for assisting a human observer, but cannot be easily
transformed in an algorithm suitable for a fully automated observation
campaign.
,
then plotting these points, is therefore very
effective for assisting a human observer, but cannot be easily
transformed in an algorithm suitable for a fully automated observation
campaign.
 |
 |
For the purpose of recovering lost asteroids, the semi-linear confidence boundary is very effective for the planning of a recovery observation campaign. The main reason is that the total area of the region indicated by this curve is, in most cases, not very large; the region is typically very elongated (after all, it is the nonlinear equivalent of an ellipse with very uneven semiaxes), and even when the length is tens of degrees, the width can be only a few arc seconds. Thus an observation campaign can be planned essentially by following the line of variation, which is the image of the major axis of the ellipse KX; there is little use in blinking large frames. This technique allows to use telescopes with small field of view (and small CCD cameras), even when the uncertainty is large; this is practically important, because recoveries can be done by either good amateur or small professional observatories, leaving the big telescopes and big cameras free to pursue surveys.
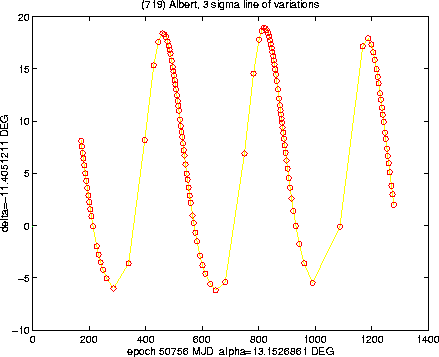
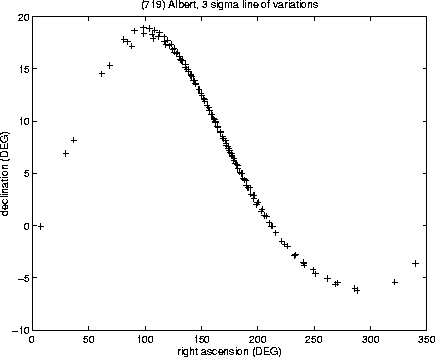
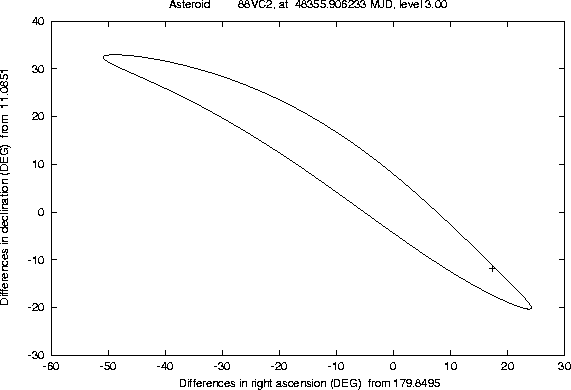
The examples in the Figures 6-9 show the
cases of some lost asteroids; we begin with the most infamous case,
(719) Albert, the only numbered asteroid which is still lost,
after having been observed upon only one opposition (and therefore
violating the present rules for numbering asteroids!). Since the
observations of Albert were performed in September/October 1911,
the asteroid is now very much lost, its position being uncertain by
more than one full revolution (Figure 6); however, if
these predictions are mapped on the celestial sphere, the uncertainty
by a multiple of ![]() does not matter, and the region to be
explored is a narrow strip, making a full tour of the sky
(Figure 7). We need to warn the observers willing to
search for Albert that, this being one of the worst cases, we
cannot exclude that our prediction of the confidence region could be
optimistic, due to normalisation problems. This a mathematical way of
saying that the original observations were likely to be of very poor
quality, and therefore the value of
does not matter, and the region to be
explored is a narrow strip, making a full tour of the sky
(Figure 7). We need to warn the observers willing to
search for Albert that, this being one of the worst cases, we
cannot exclude that our prediction of the confidence region could be
optimistic, due to normalisation problems. This a mathematical way of
saying that the original observations were likely to be of very poor
quality, and therefore the value of ![]() to be chosen is likely to
be more than the standard
to be chosen is likely to
be more than the standard ![]() ,
which has also been used in
Figures 6-7.
,
which has also been used in
Figures 6-7.
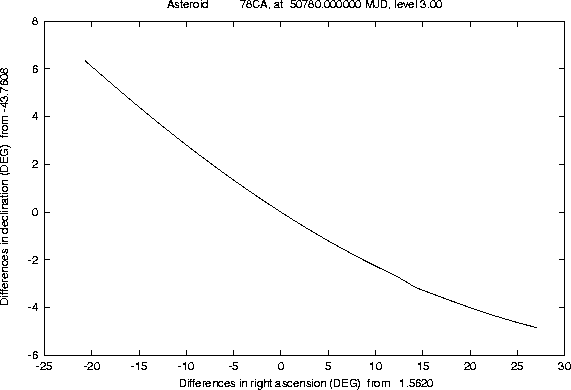
The other figures show a sample of lost asteroids, taken from the Unusual Minor Planets list issued by the Minor Planets Center (MPC) in the Minor Planets Electronic Circular 1997-V27 (November 13, 1997); this is a kind of ``most wanted list'' for lost asteroids. Predictions of the confidence boundary such as Figure 8 make perfectly clear that the asteroids from this list which have been lost for many years cannot be recovered by using only the ``central'' prediction supplied by the MPC; even the linear approximation would fail, in cases such as these, to provide the good region to look at. Both professional and good amateur astronomers know since many years that the lost asteroids have to be searched for along the line of variations, but they normally use a simple approximation to compute this line (by varying only the asteroid mean anomaly). This approximation is good enough in many cases, when a short arc asteroid has been lost since a long time, but sometimes fails, especially in the case of near-Earth asteroids lost not too long ago (as in Figure 9).
 |
 |
The experiments performed with asteroids actually recovered, such as the ones documented in Figures 1-5, give us some confidence that even asteroids which are lost in a very severe way, with predictions uncertain by several degrees, could be recovered provided the observers are tenacious enough to survey the entire confidence region, which is not impossible in the cases in which the total area is not too large. However, the problem of attribution arises; namely, how many other asteroids would be serendipitously found in the same area? An example of a false attribution is shown in Figure 10; this is an especially nasty case, in which it is difficult to disprove the attribution even by using several observations (a ``false identification'' with Q=3605.3 as least squares solution; such cases are discussed in [Sansaturio et al. 1996]), but it is clear that such false attributions can occur. A simple way to discard many false attributions arising by the simple comparison of the observation with the confidence boundary would be to use data on the proper motion, but we have not yet a tested algorithm for this.
 |