


Next: 2. The filtering procedure
Up: THE ASTEROID IDENTIFICATION PROBLEM
Previous: THE ASTEROID IDENTIFICATION PROBLEM
The general problem of asteroid identification aims at detecting cases
in which the same physical object has been observed in two arcs,
separated in time, without an a priori knowledge that they were the
same. The algorithms being used, by our group as well as by others,
to achieve identifications are many and very different. The main
distinction is whether the possible identifications are selected by
proximity in the observations space or by proximity in the phase space
of orbital elements. Since the algorithms in these two cases are very
different, we prefer to use distinct words, following the definitions
given in the first paper of this series [Milani 1999] and corresponding
to the distinction between different identification procedures in
[Marsden 1985]. An orbit identification is a case in which
the observational data of both arcs are sufficient to separately solve
for two orbits, one for each arc; then the input data are two sets of
orbital elements, and the identifications are proposed on the basis of
some measure of similarity of the orbits (which is not just the size
of the difference in the orbital elements; [Milani et al. 2000a]). In
contrast, a linkage joins together two observed arcs, each one
over a too short time span and/or with too few observations to allow
for a meaningful orbit determination, in such a way that the two
together are enough to compute an orbit. The third case is mixed:
an attribution is obtained by comparing an amount of
observational data, insufficient to compute a reliable orbit for one
arc, to the orbit already computed for the other arc. As a matter of
principle, this goal is obtained by predicting observations, based
upon the orbit which is known for one arc, and then comparing with the
observed data for a second arc.
It is important to realize that attributions sometimes are very
simple, and sometimes are very difficult. When the time span of the
better observed arc is very long, covering several apparitions, the
predictions of the observations can be very accurate and the
conjectured attribution is obtained by a simple comparison: the data
either are or are not consistent with the prediction, within the
expected observational errors. We find this kind of situation when,
for example,
observations are attributed to numbered asteroid orbits. In
contrast, the shorter the time span of the arc used to compute an
orbit, the larger the uncertainty of the predictions. For short arc
orbits the comparison between predicted and observed values cannot be
done meaningfully unless the prediction uncertainty is accounted for
in the comparison algorithm.
If all the asteroids detected (or at least the vast majority of them)
were followed up for a time span long enough to compute a reasonable
orbit, then orbit identification would be a more effective algorithm
because it indeed exploits more information; in intuitive terms, the
comparison taking place in a six dimensional space can provide tighter
constraints than a comparison in a two dimensional space (the
celestial sphere). Unfortunately the majority of asteroid discoveries
are not followed up after either one or just a few nights. This fact
results from priority being given only to discovery observations, as
opposed to observations allowing recovery and good orbit
determination, in giving credit to the observers. It is also a
consequence of the pressure to preferentially follow up unusual
objects.
Let us take as an example the dataset of asteroid astrometric
observations made public by the Minor Planet Center (MPC) on April 18,
2000. Out of 135,435 provisional designations (corresponding to
independent discoveries of asteroids still unnumbered) there were
14,416 with observed arc shorter than 12 hours (pre-1992 ``one night
stands''), 19,062 longer than 12 but shorter than 36 hours
(observations in two consecutive nights), and 18,435 longer than 36
hours and shorter than 60. The reasons for a larger number of two
nighters has to do with the criterion used by the MPC to assign a new
designation, which was modified in 1992 to the effect that a one night
stand is no longer provided with a provisional designation.
Essentially none of the one night stands since 1992 are currently
made available by the MPC for outside analysis.
Although we have successfully applied an orbit identification
algorithm even to orbits based upon observed arcs of 2-4 days, for
roughly three out of four of the designations with arcs between 2 and
4 days we are not currently computing any orbit at all1. Thus, limiting the identification algorithms to the orbit
identification case would represent a significant decrease of the
opportunities of identification.
As long as the residuals (observations, conjectured to belong to the
same object, minus prediction) are small enough, the linear formalism
of normal and covariance matrices provides a rigorous and
comparatively efficient algorithm to assess the likelihood of an
attribution. Nonlinear methods are available to deal with cases in
which the residuals are well outside the linearity region, e.g., the
semilinear method of [Milani 1999]. Indeed, these methods have been
successfully used when the problem is to investigate the suitability
of a specific attribution, as it is the case when the observations
belong to a targeted recovery of the same object. Much more
challenging is to propose attributions, that is to start from a
large catalog of orbits and a large catalog of short arc observations
and to select a reasonable number of couplings between them, to be
confirmed by a more detailed analysis of each case. Using again the
data from the April 2000 monthly update, we have computed 67,324
unnumbered asteroid orbits, and have generated 74,656
attributables (this term is better explained in Section 2) that might
be linked to the unnumbered orbits. This means we should, in
principle, perform about
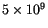 comparisons.
This large number of pairs to be tested implies that there are two
problems to be considered distinctly. On one hand we would like to
define rigorous algorithms to filter out, among the huge number of
orbit-attributable pairs, the ones that could correspond to the
same object. On the other hand, the computational efficiency of the
filtering procedure is critical to apply the algorithms with
reasonable computing resources.
This paper contains the definition of a procedure for selecting
orbit-attributable pairs and reports on the practical tests
performed in about one year of operation. The main feature of this
procedure is that it consists of a three stage filtering, with the
pairs passing the first filter further analyzed with the second
filter and finally the ones passed by the second filter confirmed by
accurate least squares fit. Thus, unlike the procedure for orbit
identifications of [Milani et al. 2000a], the three stages are qualitatively
different, and they require different strategies for optimization.
Orbit identification algorithms are discussed in [Milani et al. 2000a], but
there is one interaction with attributions that needs to be discussed
here: after an identification has been found, with any one of the two
algorithms, this new orbit can be used to search for attributions to
it. Since in most cases the orbit resulting from an identification is
multi-opposition, the uncertainty will be much smaller and additional
attributions, if they indeed exist in the observations archives, are
comparatively easy to add. However, this
scheme requires the implementation of a
recursive procedure with considerable efficiency problems. We discuss
here the extent to which the entire sequence of procedures for orbit
identification, attribution, and attribution to identification can be
automated.
This paper is organized as follows: Section 2 describes
the three stage filtering procedure, Section 3
discusses the results of the application of this procedure for about
one year and analyzes the properties of the identifications found in
this way. Section 4 contains an overall appraisal
of the results, a comparison with the results obtained by other
groups and some indications on the open problems to be solved to
further increase the efficiency and the productivity of searches
for identifications.
comparisons.
This large number of pairs to be tested implies that there are two
problems to be considered distinctly. On one hand we would like to
define rigorous algorithms to filter out, among the huge number of
orbit-attributable pairs, the ones that could correspond to the
same object. On the other hand, the computational efficiency of the
filtering procedure is critical to apply the algorithms with
reasonable computing resources.
This paper contains the definition of a procedure for selecting
orbit-attributable pairs and reports on the practical tests
performed in about one year of operation. The main feature of this
procedure is that it consists of a three stage filtering, with the
pairs passing the first filter further analyzed with the second
filter and finally the ones passed by the second filter confirmed by
accurate least squares fit. Thus, unlike the procedure for orbit
identifications of [Milani et al. 2000a], the three stages are qualitatively
different, and they require different strategies for optimization.
Orbit identification algorithms are discussed in [Milani et al. 2000a], but
there is one interaction with attributions that needs to be discussed
here: after an identification has been found, with any one of the two
algorithms, this new orbit can be used to search for attributions to
it. Since in most cases the orbit resulting from an identification is
multi-opposition, the uncertainty will be much smaller and additional
attributions, if they indeed exist in the observations archives, are
comparatively easy to add. However, this
scheme requires the implementation of a
recursive procedure with considerable efficiency problems. We discuss
here the extent to which the entire sequence of procedures for orbit
identification, attribution, and attribution to identification can be
automated.
This paper is organized as follows: Section 2 describes
the three stage filtering procedure, Section 3
discusses the results of the application of this procedure for about
one year and analyzes the properties of the identifications found in
this way. Section 4 contains an overall appraisal
of the results, a comparison with the results obtained by other
groups and some indications on the open problems to be solved to
further increase the efficiency and the productivity of searches
for identifications.
Next: 2. The filtering procedure
Up: THE ASTEROID IDENTIFICATION PROBLEM
Previous: THE ASTEROID IDENTIFICATION PROBLEM
Andrea Milani
2001-12-31